«Мы совершили фундаментальный прорыв на нижнем уровне: нативный 3D ViT¹ — по-настоящему трехмерный визуальный кодировщик. Мы пытаемся ответить на один вопрос: людям водить машину вроде бы не так уж и сложно. Любой обычный человек может вести автомобиль быстро и плавно. Но ведущие мировые компании вложили в это сотни миллиардов, а беспилотное вождение до сих пор продвигается медленно» - объяснил основатель компании Ли Сян | Li Xiang в своем посте в социальной сети Weibo.
В чем же именно проблема?
Всё это время мы учили ИИ делать взрослые дела, но так и не дали ему побыть ребенком.Человек учится ходить, бросать и ловить мяч в возрасте от 0 до 6 лет. Кажется, что это простые действия, но на самом деле именно они помогают ребенку сформировать понимание трехмерного физического пространства. Именно поэтому мы способны точно оценивать расстояние и уверенно управлять машиной — наше «3D-предобучение» завершилось еще до шести лет.
Однако все современные сквозные (end-to-end) системы по сути «учатся водить, просматривая 2D-видео». Это больше похоже на человека, который сидит перед компьютером, смотрит 100 000 часов записей с видеорегистратора, а потом сразу садится за руль. У такого ИИ есть интеллект, но он далек от человеческого.
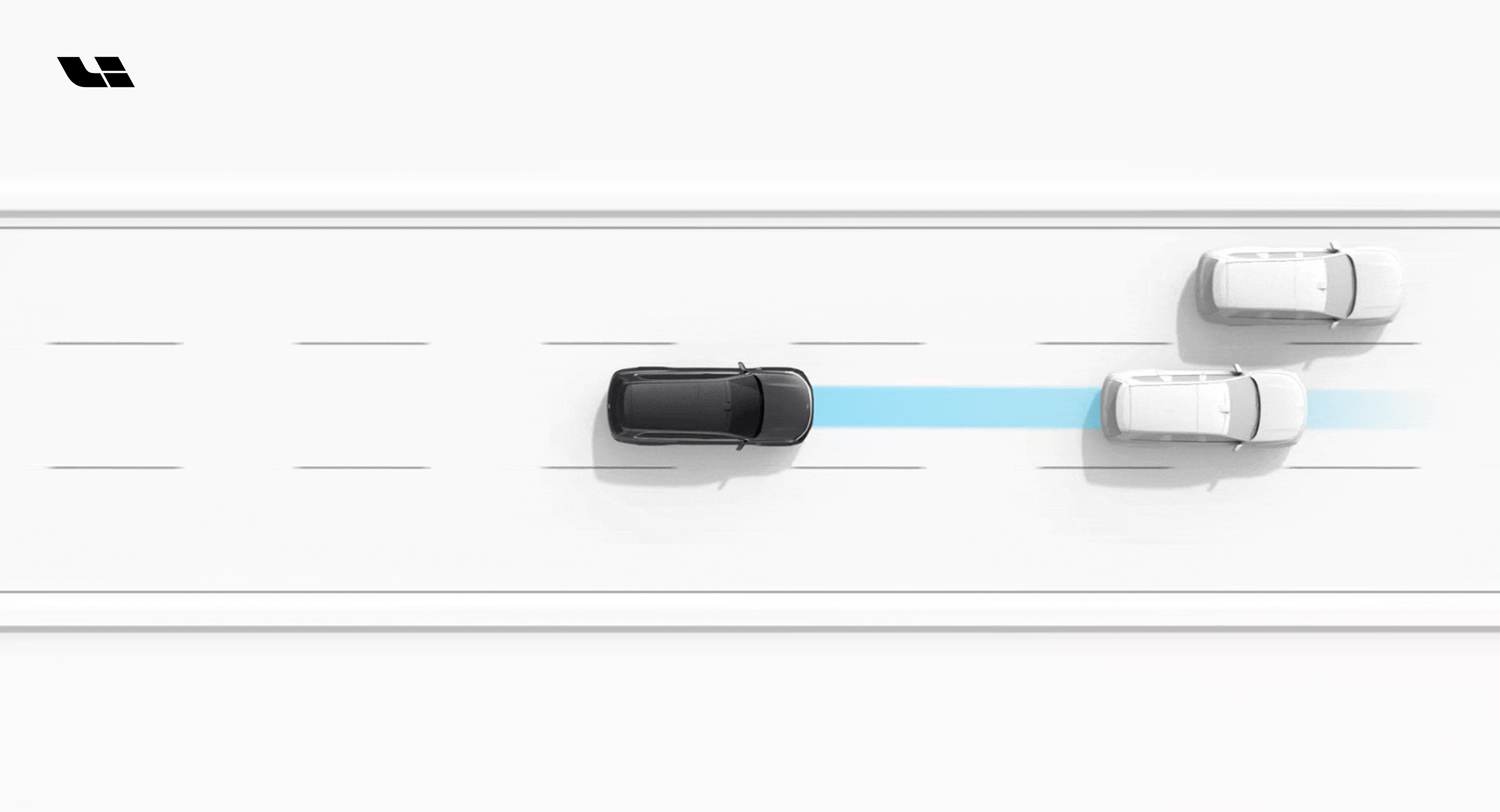
Использовавшийся нами и индустрией ранее подход «с высоты птичьего полета» делал мир плоским. Глядя на него сверху, система теряла информацию о высоте. OCC³-метод действительно работает с 3D, но ему не хватает семантической информации. Проблема ИИ в работе с физическими объектами не в более крупной модели или большем объеме данных, а в отсутствии визуального фундамента для подлинного понимания трехмерного мира. 3D ViT¹ решает эту задачу. Модель не «восстанавливает» 3D из 2D-картинок, а изначально работает в реальном трехмерном мире. С высокоточным мультиракурсным зрением в качестве основы, она выполняет унифицированное понимание 3D-геометрии и семантики пространства — его структуры, взаимного расположения объектов, смыслового наполнения — непосредственно на этапе кодирования. Модель не просто видит изображение, она понимает мир, осознавая, где что находится и чем оно является.
В рамках этой архитектуры меняется роль лидара. Он больше не является ядром восприятия, а выступает скорее высокоточной линейкой, обеспечивающей геометрическую калибровку и пространственные ограничения в ближней зоне для зрения. Теперь верхний предел возможностей системы определяет не количество физических лучей сенсора, а способность модели к характеризации (описанию данных). Благодаря единому моделированию, 3D ViT¹ способен стабильно распознавать и анализировать пространство на дистанции более 500 метров.
Дело не в том, что раньше никто не хотел этого делать — это было просто невозможно, так как 3D ViT¹ предъявляет экстремально высокие требования к вычислительной мощности автомобиля. Наш чип собственной разработки Mach обладает втрое большей эффективной мощностью, чем предыдущее поколение, что позволяет реально внедрить эту архитектуру в серийный автомобиль.
Благодаря поддержке 3D ViT¹, модель MindVLA-о1 объединяет пространственное понимание, мышление, логический вывод и манеру вождения в одной нейросети. Она не просто видит мир, но и способна моделировать изменения сцены на несколько секунд раньше даже в скрытом пространстве, “продумывая” маневр перед его началом. Эту способность мы называем мультимодальным мышлением.
Мы также подтвердили, что эта базовая модель создана не только для автопилота. Одна и та же база VLA² может как управлять автомобилями, так и контролировать роботов, превращаясь в универсального агента физического мира.
Автопилот — это лишь отправная точка для создания физического ИИ.





